1. Competiton Info
Overview
- 문서 타입 데이터셋을 이용해 이미지 분류를 모델을 구축하여 주어진 문서 이미지를 입력 받아 17개의 클래스 중 정답을 예측.
- 문서 타입 분류를 위한 이미지 분류 대회
- 문서 데이터는 금융, 의료, 보험, 물류 등 산업 전반에 가장 많은 데이터이며, 많은 대기업에서 디지털 혁신을 위해 문서 유형을 분류하고자 함.
- 문서 타입 분류는 의료, 금융 등 여러 비즈니스 분야에서 대량의 문서 이미지를 식별하고 자동화 처리를 가능케 할 수 있음.
- computer vision domain에서 가장 중요한 태스크인 이미지 분류 대회.
- computer vision에서 중요한 backbone 모델들을 실제 활용해보고, 좋은 성능을 가지는 모델 개발 및 그 밖에 학습했던 여러 테크닉들을 적용 가능
- 이미지 분류란
- 주어진 이미지를 여러 클래스 중 하나로 분류하는 작업
- 의료, 패션, 보안 등 여러 현업에서 기초적으로 활용되는 태스크
- 딥러닝과 컴퓨터 비전 기술의 발전으로 인한 뛰어난 성능을 통해 현업에서 많은 가치를 창출하고 있음.
- computer vision에서 중요한 backbone 모델들을 실제 활용해보고, 좋은 성능을 가지는 모델 개발 및 그 밖에 학습했던 여러 테크닉들을 적용 가능

2.Timeline
- 2024.07.30 - Start Date
- 2024.08.11 - Final submission deadline
3. Data descrption
Dataset overview
- 총 17개 종의 문서로 분류됨.
- 1570장의 학습 이미지를 통해 3140장의 평가 이미지를 예측
- 현업에서 사용하는 실 데이터를 기반으로 대회를 제작하여 대회와 현업의 갭을 최대한 줄이고 현업에서 생길 수 있는 여러 문서 상태에 대한 이미지를 구축

- 주어진 학습 데이터에 대한 정보는 다음과 같음.
- train/
- 1570장의 이미지가 저장.
- train.csv
- 1570개의 행으로 이루어져 있고 train/ 폴더에 존재하는 1570개의 이미지에 대한 정답 클래스를 제공
- ID 학습 샘플의 파일명
- target 학습 샘플의 정답 클래스 번호
-

- train/
EDA
- class 별 학습데이터의 양이 고르지 못함.

- 이미지들의 사이즈 분포 시각화.

Data Processing
- 학습 데이터에 오분류된 데이터 확인하여 label 수정

- 학습 데이터는 대체로 clean한 반면 평가 데이터는 상/하/좌/우 반전 및 회전등이 적용된 noise 데이터 확인
- 직사각형 이미지 99%
Data Augmentation
- 평가 데이터 셋에 대한 분석을 통해 'augraphy' 의 다양한 기능 적용
- 윤곽선 감지를 사용하여 텍스트 선을 감지하고 부드러운 텍스트 취소선, 강조 또는 밑줄 효과 추가
- 이미지에 낙서 적용
- 입력 용지의 색상 변경
- 잉크 번짐 효과 (두 이미지 혼합하여 블리드스루 효과)
- 접기 효과
- 조명 또는 밝기 그래디언트
- 종이 표면에 그림자 효과
- 크기 조정(resizing), 뒤집기(flips), 회전(rotation) 등 기본적인 기하학적 변환 적용
- torchvision.transforms v1과 호환되는 v2 사용
- 적용 전

- 적용 후

4. Modeling
Model descrition
- EfficientNet_b4
- SWIN(Shifted Window)
- ConvNeXt
- OCR
<EfficientNet 모델>
EfficientNet은 이미지 분류와 같은 컴퓨터 비전 태스크를 위한 딥러닝 모델입니다. 이 모델은 기존의 ConvNet 모델들을 효율적으로 확장할 수 있는 방법을 제시하여, 정확도와 연산 효율성의 균형을 최적화합니다.
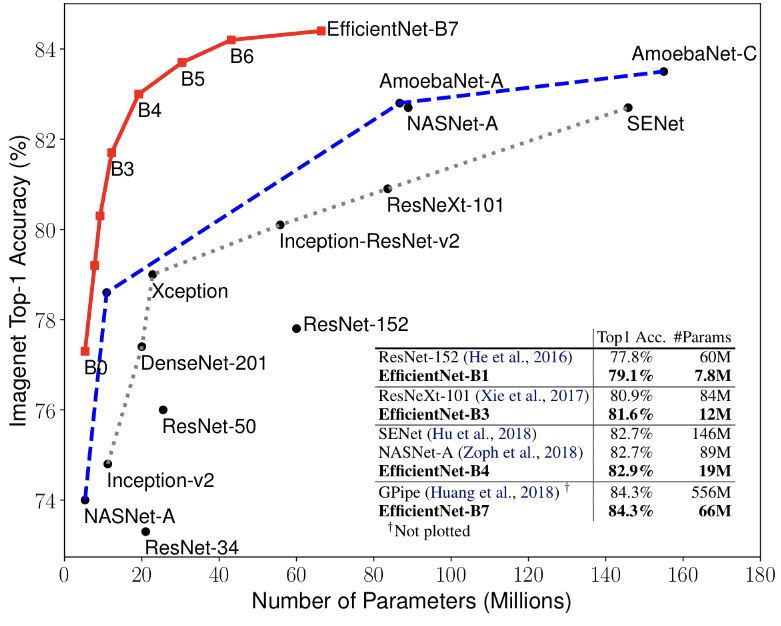
EfficientNet 소개
EfficientNet은 성능과 효율성을 동시에 고려하여 개발된 모델로, MobileNet과 ResNet을 포함한 기존의 모델들을 대체할 수 있는 경쟁력 있는 선택지입니다. EfficientNet은 모델의 크기를 확장하면서도, 성능의 감소 없이 계산 복잡도를 줄이는 데 중점을 둡니다.
확장 전략: Compound Scaling
EfficientNet의 핵심 개념은 Compound Scaling입니다. 이는 모델의 너비(width), 깊이(depth), 해상도(resolution)를 균형 있게 확장하여 최적의 성능을 달성하는 방법입니다.
- 너비(width): 네트워크의 채널 수를 증가시켜 더 많은 특징을 학습
- 깊이(depth): 네트워크의 레이어 수를 증가시켜 더 깊은 특징을 학습
- 해상도(resolution): 입력 이미지의 해상도를 높여 더 세밀한 정보를 학습
이러한 확장 전략은 단순히 하나의 요소만을 확장하는 기존 방법과 달리, 세 가지 요소를 동시에 조정하여 더 효율적인 모델을 만듭니다.
모델 아키텍처
EfficientNet은 MBConv라는 모바일 친화적인 블록을 사용합니다. 이는 기존의 Convolutional Layer보다 적은 연산으로 동일한 성능을 달성하는 핵심 요소입니다.
| Stage | 해상도 | 채널 수 |
|---|---|---|
| 1 | H/2 × W/2 | 16C |
| 2 | H/4 × W/4 | 24C |
| 3 | H/8 × W/8 | 40C |
| 4 | H/16 × W/16 | 80C |
| 5 | H/32 × W/32 | 112C |
| 6 | H/64 × W/64 | 192C |
| 7 | H/128 × W/128 | 320C |
효율적인 연산
EfficientNet은 다음과 같은 요소를 통해 연산 효율성을 극대화합니다:
- MBConv Block: 깊이별 분리 합성곱(Depthwise Separable Convolution)과 Squeeze-and-Excitation 기법을 결합하여 성능과 효율성을 높임
- 스케일링 방법: 너비, 깊이, 해상도의 조합을 통해 연산량 대비 성능을 최적화
비교 및 성능
EfficientNet은 기존의 모델들과 비교하여 더 적은 파라미터와 FLOPs(Floating Point Operations)로 유사하거나 더 나은 성능을 제공합니다. 예를 들어, EfficientNet-B7 모델은 ImageNet 데이터셋에서 매우 높은 정확도를 기록하면서도, ResNet-50과 같은 기존 모델들보다 훨씬 적은 연산량을 요구합니다.
활용 사례
EfficientNet은 다양한 컴퓨터 비전 태스크에서 사용될 수 있습니다. 예를 들어:
- 이미지 분류
- 객체 탐지(Object Detection)
- 세그멘테이션(Segmentation)
EfficientNet의 효율적인 연산 구조 덕분에, 모바일 기기와 같이 자원이 제한된 환경에서도 탁월한 성능을 발휘할 수 있습니다.
수학적 표현
EfficientNet에서 사용되는 주요 연산은 다음과 같습니다:
$$
Y = \text{Conv}(X, W) + B
$$
여기서:
- $X$는 입력 데이터
- $W$는 가중치
- $B$는 편향(bias)
- $\text{Conv}$는 합성곱 연산을 의미
모델 복잡도 및 파라미터 수
EfficientNet은 다양한 버전(B0 ~ B7)으로 제공되며, 각 버전은 모델의 복잡도와 성능이 다릅니다. 모델의 파라미터 수와 FLOPs는 이미지 해상도와 네트워크 깊이에 비례하여 증가합니다.
- EfficientNet-B0: 기본 모델, 약 5.3M 파라미터
- EfficientNet-B7: 확장된 모델, 약 66M 파라미터
EfficientNet은 파라미터 수와 계산량이 증가하면서도 선형적으로 성능이 향상되는 특성을 보입니다.
EfficientNet은 성능과 효율성의 균형을 최적화한 모델로, 컴퓨터 비전 분야에서 다양한 응용이 가능합니다.
SWIN (Shifted Window) 모델
SWIN은 컴퓨터 비전 태스크를 위한 딥 러닝 아키텍처입니다. CNN의 지역성과 Transformer의 전역 정보 처리 능력을 결합하여 효율적이고 강력한 성능을 제공합니다.

이미지 분할 및 임베딩
- 입력 이미지 (H×W×3)를 작은 패치로 분할
- 각 패치를 선형 임베딩으로 고차원 벡터로 변환
계층적 특징 추출
모델은 4개의 stage로 구성되며, 각 stage에서 이미지 해상도와 채널 수가 변화합니다:
| Stage | 해상도 | 채널 수 |
|---|---|---|
| 1 | H/4 × W/4 | 48C |
| 2 | H/8 × W/8 | 2C |
| 3 | H/16 × W/16 | 4C |
| 4 | H/32 × W/32 | 8C |
Swin Transformer Block
각 stage의 핵심 구성 요소:
- Window Multi-head Self Attention (W-MSA)
- Shifted Window Multi-head Self Attention (SW-MSA)
- Multi-Layer Perceptron (MLP)
- Layer Normalization (LN)
윈도우 기반 self-attention
- 전체 이미지 대신 작은 윈도우 내에서 self-attention 수행
- 계산 복잡도: O(n^2)에서 O(n)으로 감소
- n: 전체 토큰 수
- M: 윈도우 크기
Shifted Window 메커니즘
- 연속된 층에서 윈도우 위치를 교대로 이동
- 윈도우 간 정보 교환 가능
패치 병합 (Patch Merging)
- 각 stage 사이에 적용
- 공간 해상도를 줄이고 채널 수를 증가
- 인접한 2×2 패치의 특징을 연결하고 선형 변환 적용
수학적 표현
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V
$$
여기서:
- $Q$, $K$, $V$는 각각 Query, Key, Value 행렬
- $d$는 임베딩 차원
모델 복잡도
- 파라미터 수와 계산량이 이미지 크기에 선형적으로 비례
- 기존 Vision Transformer의 제곱 복잡도보다 효율적
SWIN 모델은 효율성과 성능을 모두 고려한 설계로, 다양한 컴퓨터 비전 태스크에서 우수한 결과를 보여줍니다.
ConvNeXt V2 모델
ConvNeXt V2는 비전 태스크를 위한 CNN 아키텍처입니다. 이 모델은 ConvNeXt의 개선된 버전으로, Transformer의 강점을 CNN 구조에 효과적으로 통합하여 뛰어난 성능과 효율성을 가집니다.
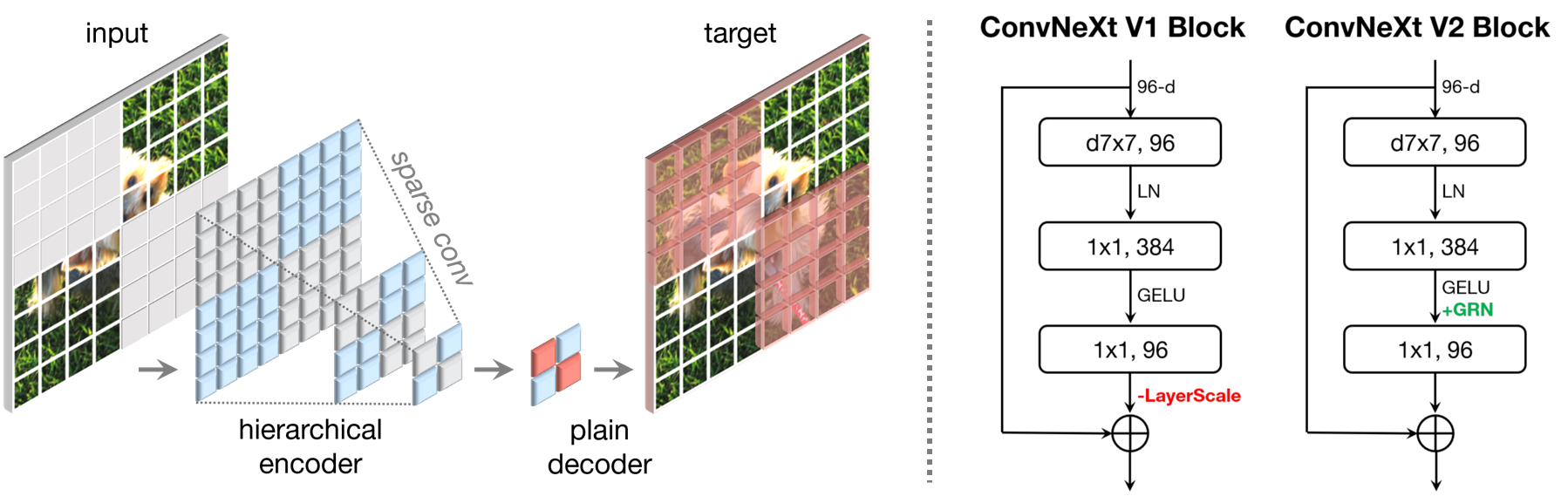
모델 개요
ConvNeXt V2는 다음과 같은 특징을 가진 최신 CNN 아키텍처입니다:
- ConvNeXt의 개선된 버전으로, 더욱 강력한 성능 제공
- CNN의 계산 효율성과 Transformer의 강력한 표현력을 결합
- 이미지 분류, 객체 탐지, 세그멘테이션 등 다양한 비전 태스크에 적용 가능
- 최신 딥러닝 기술을 통합하여 성능과 효율성 향상
주요 구성 요소
ConvNeXt V2의 핵심 구성 요소는 다음과 같습니다:
- Fully Convolutional 설계
- Global Response Normalization (GRN)
- Inverted Bottleneck
- Scaled Dot-Product Attention (SDPA)
각 구성 요소는 모델의 성능과 효율성 향상에 중요한 역할을 합니다.
Fully Convolutional 설계
ConvNeXt V2는 전통적인 CNN 구조를 기반으로 하되, 다음과 같은 혁신적인 설계를 적용했습니다:
- 7x7 depthwise convolution 사용으로 넓은 수용 영역 확보
- 채널 간 정보 교환을 위한 1x1 convolution 적용
- 전체적으로 fully convolutional 구조를 유지하여 다양한 입력 크기에 대응 가능
이러한 설계는 모델의 유연성과 성능을 동시에 향상시킵니다.
Global Response Normalization (GRN)
GRN은 ConvNeXt V2의 핵심 중 하나로, 다음과 같은 특징을 가집니다:
- 채널 간 의존성을 효과적으로 모델링
- 특징 맵의 전역적 정보를 활용하여 local response normalization의 한계 극복
- 수식:여기서 $x$는 입력 특징, $\gamma$는 학습 가능한 파라미터, $N$은 채널 수
- $$y = x \cdot \left(1 + \gamma \cdot \left(\frac{\sum x^2}{N}\right)^{0.5}\right)$$
Inverted Bottleneck
Inverted Bottleneck 구조는 MobileNetV2에서 영감을 받아 설계되었으며, 다음과 같은 이점을 제공합니다:
- 채널 수를 일시적으로 확장했다가 다시 축소하는 방식
- 계산 효율성 향상 및 모델의 표현력 증가
- 적은 파라미터로 복잡한 특징을 효과적으로 학습 가능
이 구조는 모델의 경량화와 성능 향상에 크게 기여합니다.
Scaled Dot-Product Attention (SDPA)
SDPA는 Transformer에서 영감을 받은 주의 메커니즘으로, 다음과 같은 특징을 가집니다:
- 전역적 의존성을 효과적으로 모델링
- 특징 맵의 서로 다른 영역 간의 관계를 학습
계층적 구조
ConvNeXt V2는 4개의 stage로 구성된 계층적 구조를 가집니다:
| Stage | 출력 크기 | 채널 수 |
|---|---|---|
| 1 | H/4 × W/4 | 96 |
| 2 | H/8 × W/8 | 192 |
| 3 | H/16 × W/16 | 384 |
| 4 | H/32 × W/32 | 768 |
각 stage는 여러 개의 ConvNeXt V2 블록으로 구성되며, 이러한 계층적 구조는 다양한 스케일의 특징을 효과적으로 학습할 수 있게 해줍니다.
모델 복잡도
ConvNeXt V2는 효율적인 설계로 다음과 같은 특징을 가집니다:
- 파라미터 수와 계산량이 이미지 크기에 선형적으로 비례
- ViT와 같은 Transformer 모델보다 높은 계산 효율성
- 다양한 크기의 모델 제공 (Tiny, Small, Base, Large)로 서로 다른 요구사항에 대응
이러한 특성은 ConvNeXt V2를 다양한 환경과 하드웨어에서 유연하게 사용할 수 있게 합니다.
성능 및 응용
ConvNeXt V2는 다양한 컴퓨터 비전 태스크에서 우수한 성능을 보여줍니다:
- ImageNet 분류에서 최고 수준의 정확도 달성
- COCO 객체 탐지 및 세그멘테이션에서 뛰어난 성능
- 적은 계산 리소스로 효율적인 학습 및 추론 가능
이 모델은 자율주행, 의료 영상 분석, 로보틱스 등 다양한 실제 응용 분야에서 활용될 수 있습니다.
ConvNeXt V2는 CNN과 Transformer의 장점을 결합한 아키텍처로, 다양한 비전 문제에 대한 효과적인 모델을 제공합니다.
Modeling Process
- Augmentation으로 데이터증강하여 3개의 모델 실험
- 하이퍼파라미터 튜닝
- 데이터를 오프라인으로 증강시켜 학습. (약 25000개)
- 평가데이터 Denoising
- 훈련데이터중 일부도 Denosing
- Paddle OCR을 이용한 단어 추출 후 단어사전을 만들어 분류 (3, 4, 7, 14 클래스만 적용함)
5. Result
Leader Board
- 리더보드 (Public)
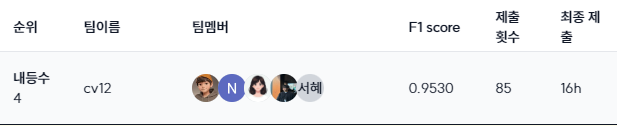
- 리더보드 (Private)

- 4등,cv12, F1_Score : 0.9530, 제출 횟수 : 85
6. 개인 회고
목차
- 학습목표를 달성하기 위해 무엇을 어떻게 했는지?
- 전과 비교해서, 내가 새롭게 시도한 변화는 무엇이고, 어떤 효과가 있었는지?
- 마주한 한계는 무엇이며, 아쉬웠던 점은 무엇인지?
- 한계/교훈을 바탕으로 다음 경진대회에서 시도해보고 싶은 점은 무엇인가?
- 협업 과정에서 잘된 점은 어떤 점이 있는가?
학습목표를 달성하기 위해 무엇을 어떻게 했는지?
- CV Basic 학습
- 7.23(화) ~ 7.29(월) CV Basic 학습
- CV Advanced 학습 & 경진대회 Dataset EDA
- 7.30(화) ~ 8.05(월)
- Image Classification 경진대회 진행
- 8.06(화) ~ 8.12(월)
전과 비교해서, 내가 새롭게 시도한 변화는 무엇이고, 어떤 효과가 있었는지?
- Hyper-parameter tuning 시, wandb의 sweep 과 optuna 적극 활용
- Baseline code에서 주어진 Data Augmentation 라이브러리인 'albumentations'를 그대로 사용하지 않고 EDA를 통해 다양한 효과를 줄 수 있는 'augraphy'를 적용하는 것이 더 낫겠다는 판단을 통해 torchvision의 transforms v2와 함께 적용한 1570개의 데이터로 리더보드 제출점수 Macro F1 Score Public: 0.9181 Private: 0.9070 나옴
- 학습 데이터를 10000개 이상 늘린 다른 팀원 보다 높은 점수 획득
- cv2를 이용한 imread()와 PIL을 이용한 Image.open() 의 차이 이해
- transform pipeline의 입출력 데이터 이해
- ResNet, EfficientNet_V1 / V2, ConvNextV2, SwinT 를 사용한 다양한 모델링
마주한 한계는 무엇이며, 아쉬웠던 점은 무엇인지?
- Upstage 제공 서버에서 num_workers > 0 적용 시 libpng 관련 에러가 발생해서 이거 해결해보겠다고 시간을 많이 허비했는데... colab은 해당 에러 발생하지 않음... 뭐지?ㅎ 정신건강을 위해서 다음 대회부터는 그냥 colab 유료버전 쓰는 걸로!
- pytorch lightning과 hydra를 적용해보고 싶었는데 모델링 하느라 시간이 부족해서 못한 부분이 좀 아쉬웠음
협업 과정에서 잘된 점은 어떤 점이 있는가?
- 팀원들과 매일 오전 10시부터 1시간가량 각자가 한 것들에 대한 스크럼을 나누는 시간에 서로 인사이트를 공유할 수 있어서 유익했음
'Upstage AI Lab 3기' 카테고리의 다른 글
| NLP(Natural Language Processing) (1) | 2024.09.23 |
|---|---|
| Computer Vision Basic, Advanced, Generation (0) | 2024.08.20 |
| Regression 경진대회 최종 2등 (0) | 2024.07.22 |
| Pytorch Environment Settings - Apple Silicon Mac (0) | 2024.07.03 |
| ML Regression 주가 예측 (0) | 2024.06.05 |
