[Upstage AI Lab] Regression 대회
1. Competiton Info
Overview
- House Price Prediction 경진대회는 주어진 데이터를 활용하여 서울의 아파트 실거래가를 효과적으로 예측하는 모델을 개발하는 대회입니다.
Timeline
- 2024년 7월 15일 (월) - 대회 시작, 각자 EDA
- 2024년 7월 16일 (월) - 각자 EDA 및 Feature Engineering
- 2024년 7월 17일 (수) - 최종 데이터셋 설정 및 Modeling
- 2024년 7월 18일 (목) - Feature Selection 및 Modeling Hyper-parameter tuning
- 2024년 7월 19일 (금) - 최고 성능 모델 추가 처리 및 최종 제출 기한
Evaluation
- 아파트 매매의 맥락에서는 회귀 모델이 실제 거래 가격의 차이를 얼마나 잘 잡아내는지 측정
2. Data descrption
Dataset overview
- 학습 데이터
- 주요 데이터는 .csv 형태로 제공되며, 서울시 아파트의 각 시점에서의 거래금액(만원)을 예측하는 것이 목표
- 학습 데이터는 아래와 같이 1,118,822개이며, 예측해야 할 거래금액(target)을 포함한 52개의 아파트의 정보에 대한 변수와 거래시점에 대한 변수가 주어짐
- 학습 데이터의 기간은 2007년 1월 1일부터 2023년 6월 30일까지이며, 각 변수 명이 한글로 되어있어 어떤 정보를 나타내는 변수인지 쉽게 확인 가능
- 예시)
- 시군구 : “서울특별시 강남구 개포동” 과 같이 주소에 대한 정보
- 아파트명 : “개포더샵트리에”와 같이 아파트명에 대한 정보
- 전용면적(㎡) : “108.2017”와 같이 매매대상의 전용면적에 대한 정보
- 건축년도 : “2021”과 같이 아파트의 건축 연도를 나타내는 정보
- 예시)
- 각 변수가 갖는 결측치 비율

- 아파트의 매매가를 결정하는데에 교통적인 요소가 영향을 줄 수 있기에 추가 데이터로 서울시 지하철역, 서울시 버스정류장의 정보가 주어짐
- 추가 데이터는 위도와 경도, 좌표 X와 좌표Y와 같이 거리에 대한 정보가 포함되어 있으며, 이를 활용하여 학습 데이터와 함께 사용 가능
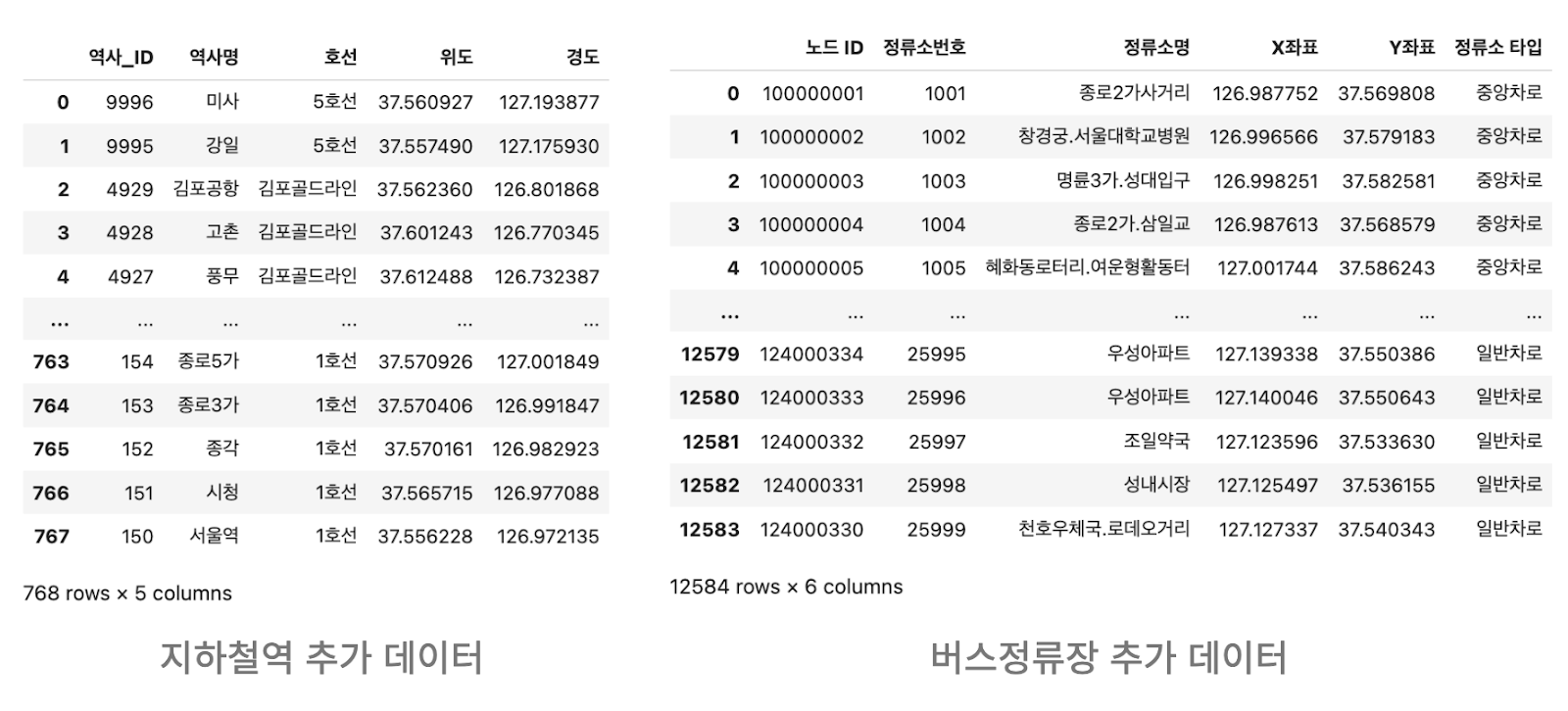
- 추가 데이터는 위도와 경도, 좌표 X와 좌표Y와 같이 거리에 대한 정보가 포함되어 있으며, 이를 활용하여 학습 데이터와 함께 사용 가능
- 평가 데이터
- .csv 형태로 제공되며 학습데이터와 같이 예측해야 할 거래금액(target)을 제외하고 51개의 거래 대상이 되는 아파트의 정보에 대한 변수와 거래시점에 대한 변수가 주어짐
- 학습 데이터의 기간은 2007년 1월 1일부터 2023년 6월 30일까지이고, 평가 데이터는 학습 데이터기간 이후 3개월인 2023년 7월 1일부터 2023년 9월 26일까지의 정보로 구성
- 학습 데이터는 1,118,822인 반면, 평가 데이터는 총 9272개이며 대략적인 구조는 아래와 동일

Data pre-processing
- 데이터 수집
- 결측치 처리 및 파생변수 생성을 위한 추가 데이터 수집
- 데이터 전처리
- EDA
- EDA 자동화 도구인 Dataprep.eda & ydata_profiling 사용
- matplotlib, seaborn 등 기존 시각화 패키지를 사용하여 세밀한 확인 추가 진행
- 각 feature 데이터의 분포 확인
- 결측치 탐지
- 타 컬럼 대비 '번지', '본번', '부번', '아파트명' 의 경우 결측률이 대략 0.2% 이내임을 파악
- 주어진 데이터셋의 '번지' 데이터 값이 '본번'-'부번' 으로 구성됨 확인
- '아파트명'의 경우 일부 숫자값 존재하여 확인 시, '번지' 값임을 확인
- 타 컬럼 대비 '번지', '본번', '부번', '아파트명' 의 경우 결측률이 대략 0.2% 이내임을 파악
- 이상치 탐지
- '도로명', '등기신청일자', '거래유형', '중개사소재지' 에 실제 결측치라고 표시되지 않았으나 아무 의미 없는 값들을 포함하여 이를 결측치로 인식할 수 있도록 변경
- '층'에 음수값이 포함됨을 확인
- '전용면적'에 대한 가격의 이상치 존재.
- 같은 '강남구'라도 160평대 아파트 평균값이 130평대 아파트의 그것보다 낮음
- EDA 자동화 도구인 Dataprep.eda & ydata_profiling 사용
- 이상치 처리
- '층'의 최솟값이 train에 -4, test에 -3 존재하여 이를 1로 대체
- 결측치 처리
- '서울시 공동주택 아파트 정보' 데이터 활용하여 아래와 같이 결측치를 대략 870000 > 250000 으로 대체
적용 전 적용 후 결측치 갯수 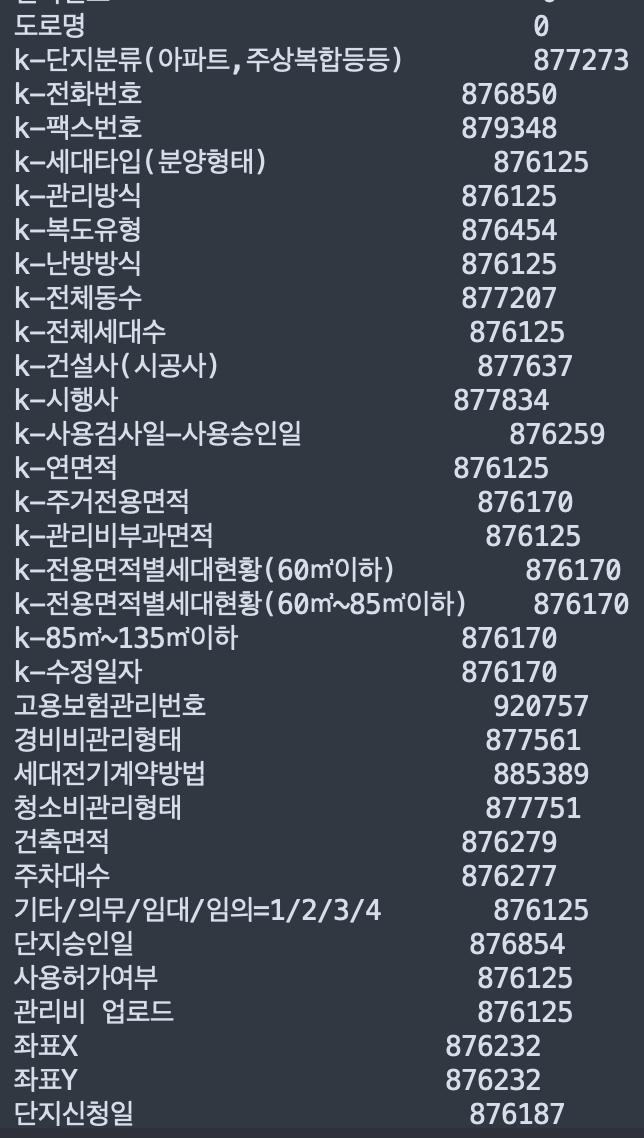

결측치율 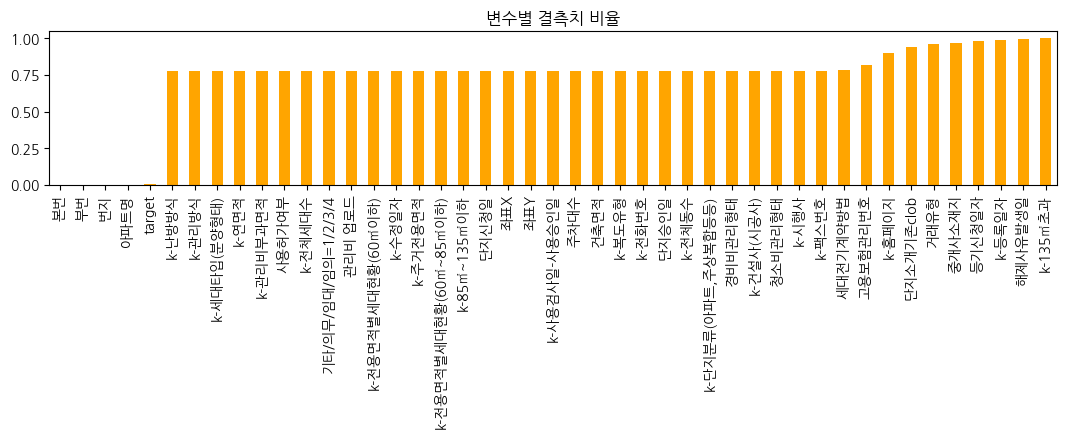
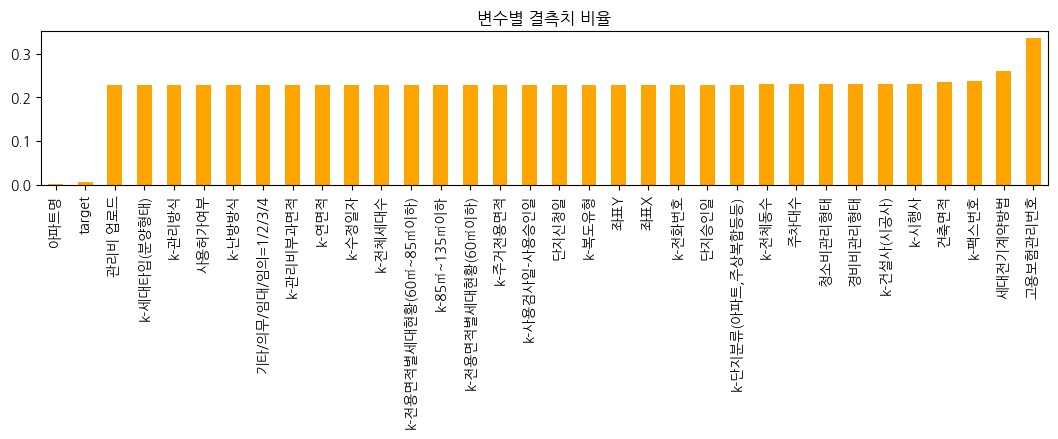
- '좌표X', '좌표Y'
- 가까운 지하철역과의 거리, 구별 대장아파트와의 거리를 계산하는데 필요한 정보로, 선형보간하는 것은 옳지 않다고 판단하여 아래와 같은 방법으로 결측치를 0으로 줄임
- 같은 아파트 명을 기준으로 도로명 결측치 보완
- 카카오 API를 활용해 '시군구' 와 '도로명' 값으로 '아파트명', '좌표X', '좌표Y' 의 결측치 대체
변수명 적용 전 적용 후 아파트명 2136 1547 좌표X 257393 23944 좌표Y 257393 23944 - 나머지 '좌표X', '좌표Y'의 23944개의 결측치는 '시군구'와 '번지'를 활용해 한땀한땀 검색하여 찾은 값으로 대체
- '번지'의 경우, 2개의 아파트에 대한 값을 찾아서 대체
- 나머지 연속형 / 범주형 변수에 대한 결측치 보간 처리
- '서울시 공동주택 아파트 정보' 데이터 활용하여 아래와 같이 결측치를 대략 870000 > 250000 으로 대체
- 파생변수 추가
- '아파트와 역과의 거리 점수'
- '지하철역의 좌표'를 활용해 각 아파트에 대해 가장 가까운 '역과의 거리'를 점수로 변환한 변수 추가
- 100미터 이내 10점, 1000미터에서 0점
- 'subway_count'
- 아파트의 반경 1km안에 존재하는 지하철역 갯수 카운팅
- '부동산 급지'
- '평단가'(전용면적 대비 실거래가)를 '동'과 '계약연도'별 그룹화 후 평균을 구한 Z-score를 기반으로 범주형 데이터로 변환한 변수 추가
- '구별 대장아파트와의 거리'
- '구별 대장 아파트의 좌표'를 활용해 각 아파트에 대해 '대장 아파트와의 거리' 변수 추가
- '시공능력평가 20위 여부'
- '건설사(시공사)'를 활용해 한땀한땀 정제하여 시공능력평가 20위(각 건설사별 아파트 브랜드 포함) 여부에 대한 변수 추가
- '이자율'
- '주택담보대출금리'를 활용해 '계약년월' 기준 '이자율' 변수 추가
- 신축여부
- 2009년 이후에 지어졌으면 비교적 신축이라고 판단
- '아파트와 역과의 거리 점수'
- 변수 선택
- Embedded methods + Wrapper method
- 모델 훈련과정에서 변수의 중요도인 Feature importance를 기준으로 feature 수를 늘려 최적의 성능이 나오는 Feature selection 진행.
- Embedded methods + Wrapper method
- EDA
3. Modeling
Model selection
- LightGBM
- 큰 데이터셋임에도 불구하고 Gradient를 기준으로 학습데이터를 down sampling하는 'GOSS'와 Bundle로 묶을 수 있는 Feature를 식별하는 단계와 Feature들을 병합하는 단계를 거쳐 입력 Feature의 수를 줄이는 'EFB' 방식을 통해 빠르게 훈련되는 장점
- 모델에서 결측값을 포함한 다양한 데이터 타입을 효과적으로 알아서 처리하는 장점
- CatBoost
- 범주형 데이터를 자동으로 처리하는 데 강점을 가지고 있어 범주형 변수를 직접 인코딩할 필요가 없음
두 모델 모두 트리 기반 모델로 비선형 관계와 상호작용을 잘 파악할 수 있으며, Feature importance를 제공하고, 과정합 방지를 위한 방법들을 제공함.
Processing
- 모델의 feature importance 추출
- feature importance가 높은 순으로 feature를 선택하여 모델 학습 후 적용한 rmse 결과 비교
- 여러방식의 k-fold 적용
- K-Fold
- TimeSeriesSplit
- Random seed KFold 등
- LGBM 과 Catboost의 결과 앙상블
Meta model
- 기준이 되는 feature에 대한 $1m^2$당 평균가격을 바탕으로 급지를 나누고 나눈 급지별로 모델을 fit한 후 결과 합침
- '동', '도로명' 두가지의 경우로 나누어 실행
- 전용면적이 큰 곳의 가격에서의 에러가 높음을 인지하고, 60평을 기준으로 데이트를 나누어 모델을 fit한 후, 결과들을 합친 후, Ridge와 같은 선형회귀모델로 결과값을 다시 계산
- 설계는 해뒀으나 너무 늦게 아이디어를 생각하게 되어 리더보드에 올려보지 못함
Hyper-parameter tunning
- 'optuna' 활용하여 최적의 파라미터 추출
- 기록 및 분석 시각화 도구인 'Weights & Biases' 활용하여 실험 기록 및 'Hyperparameter sweeps' 기능을 이용하여 하이퍼파라미터 튜닝
4. Result
Leader Board

- 2등, RMSE: 11617.5312
5. 개인 회고
가격 예측 대회 2등 성과를 통해 배운 점
이번 가격 예측 대회에서 최종 2등을 달성하며, 많은 것을 배우고 성취할 수 있었습니다. 이번 프로젝트를 통해 데이터 전처리와 모델링 기법이 모델 성능에 얼마나 큰 영향을 미칠 수 있는지를 깊이 체험할 수 있었습니다. 아래에서는 학습목표 달성 과정, 새로운 시도와 효과, 한계와 교훈을 바탕으로 다음 경진대회에서 시도해보고 싶은 점을 정리하였습니다.
1. 학습목표를 달성하기 위해 무엇을 어떻게 했는지
이번 대회의 주요 학습목표는 다음과 같았습니다:
- 결측치 처리: 주어진 데이터셋에 많은 결측치가 존재하여, 이를 효과적으로 처리하는 것이 성능 향상의 핵심이었습니다. 외부 데이터를 적극적으로 활용하여 결측치를 최대한 채웠습니다.
- EDA: 데이터를 깊이 이해하고, 시각화를 통해 데이터의 분포와 관계를 파악하고자 했습니다. 이를 위해 시각화 자동화 도구인 Dataprep.eda 패키지를 새롭게 활용했습니다.
- 모델링 실험 관리: 여러 모델링 실험을 체계적으로 관리하고 분석하기 위해 WanDB를 활용하여 실험을 기록하고 분석했습니다.
- 하이퍼파라미터 튜닝: 모델의 성능을 최적화하기 위해 WanDB의 Hyperparameter sweep 기능을 사용하여 하이퍼파라미터 튜닝을 진행했습니다.
이 목표들을 달성하기 위해, 데이터 전처리 단계에서는 EDA를 통해 데이터의 구조와 특성을 파악하고, 결측치와 이상치를 처리하였으며, 연속형 및 범주형 변수를 적절히 변환하고 새로운 파생 변수를 생성하였습니다. 또한, 변수 선택을 통해 중요한 변수만을 사용하여 모델을 학습시켰습니다.
2. 내가 새롭게 시도한 변화는 무엇이고 어떤 효과가 있었는지
이번 프로젝트에서 새롭게 시도한 변화는 다음과 같습니다:
- Dataprep.eda 활용: 이전에는 matplotlib과 seaborn을 사용하여 수동으로 시각화를 진행했으나, 이번에는 Dataprep.eda 패키지를 사용하여 EDA를 자동화하였습니다. 이를 통해 데이터의 분포, 상관관계, 결측치 패턴 등을 더 빠르고 효율적으로 파악할 수 있었습니다.
- WanDB 활용: 실험 기록과 분석을 위해 WanDB를 처음으로 도입하였습니다. 실험 결과를 체계적으로 관리하고 비교할 수 있었으며, Hyperparameter sweep 기능을 통해 자동으로 하이퍼파라미터 튜닝을 수행하여 최적의 모델을 찾을 수 있었습니다.
이러한 변화들은 모델링 과정의 효율성을 크게 향상시켰으며, 특히 EDA 단계에서의 시간 절약과 하이퍼파라미터 튜닝의 체계적인 접근 덕분에 최종 모델의 성능을 극대화할 수 있었습니다.
3. 한계/교훈을 바탕으로 다음 경진대회에서 시도해보고 싶은 점
이번 대회를 통해 몇 가지 한계와 교훈을 얻을 수 있었습니다:
- 데이터 전처리의 중요성: 데이터 전처리가 잘 되어 있는 데이터셋과 그렇지 않은 데이터셋으로 모델 훈련 시, 모델 성능이 현저히 차이나는 것을 이번 대회를 통해 체험하여 데이터 전처리의 중요성을 다시금 확실히 깨달을 수 있었습니다.
- 도메인 지식의 중요성: 도메인 지식을 활용해 여러 파생변수를 도출해낼 수 있으며 해당 변수가 모델 성능에 영향을 미치는 것을 통해 문제해결이 필요한 도메인 지식에 대한 이해가 선행될 필요성을 느꼈습니다.
- 특히 지난 Python EDA 프로젝트 때, 서울시 아파트의 급등, 급락에 영향을 주는 요인 탐색 시 얻은 인사이트를 활용하여 파생변수 생성에 도움이 되었습니다.
다음 경진대회에서는 다음과 같은 점들을 시도해보고자 합니다:
- 더 다양한 데이터 소스 탐색: 결측치 처리와 데이터 보강을 위해 더 다양한 외부 데이터 소스를 탐색하고 활용하는 방안을 연구하겠습니다.
- 도메인 지식 학습: 도메인 지식을 다 습득하기에는 한계가 있겠지만 해결하고자 하는 문제에 대한 도메인 지식에 대한 학습은 필수 선행하겠습니다.
- 지속적인 도구 학습: 이번에 새롭게 배운 도구들 외에도, 최신의 데이터 분석 및 모델링 도구들을 지속적으로 학습하고 적용하여, 더 효율적이고 효과적인 분석을 추구하겠습니다.
이번 경진대회를 통해 데이터 전처리와 모델링의 중요성을 다시 한 번 깨달았으며, 얻은 교훈을 바탕으로 앞으로 더 나은 성과를 내기 위해 노력하겠습니다.
'Upstage AI Lab 3기' 카테고리의 다른 글
| Computer Vision Basic, Advanced, Generation (0) | 2024.08.20 |
|---|---|
| Image Classification 경진대회 최종 4등 (0) | 2024.08.12 |
| Pytorch Environment Settings - Apple Silicon Mac (0) | 2024.07.03 |
| ML Regression 주가 예측 (0) | 2024.06.05 |
| 코딩테스트를 위한 자료구조 및 알고리즘 개론 (0) | 2024.05.20 |
